Abstraction without indirection
or, how Reduct approaches LLMs
To software engineers, we describe Reduct as "text-based video editing software". To documentarians and academic researchers, "infrastructure for video archives" is a more appropriate description. Often, "cheap and easy transcription" suffices. Each is true but reveals only a single facet of the tool. This variety of perspectives and uses enables us to serve very different users—anthropologists, documentarians, user experience researchers, public defenders, doctors, car manufacturers, pet shop owners, and software designers—all using the exact same interface.
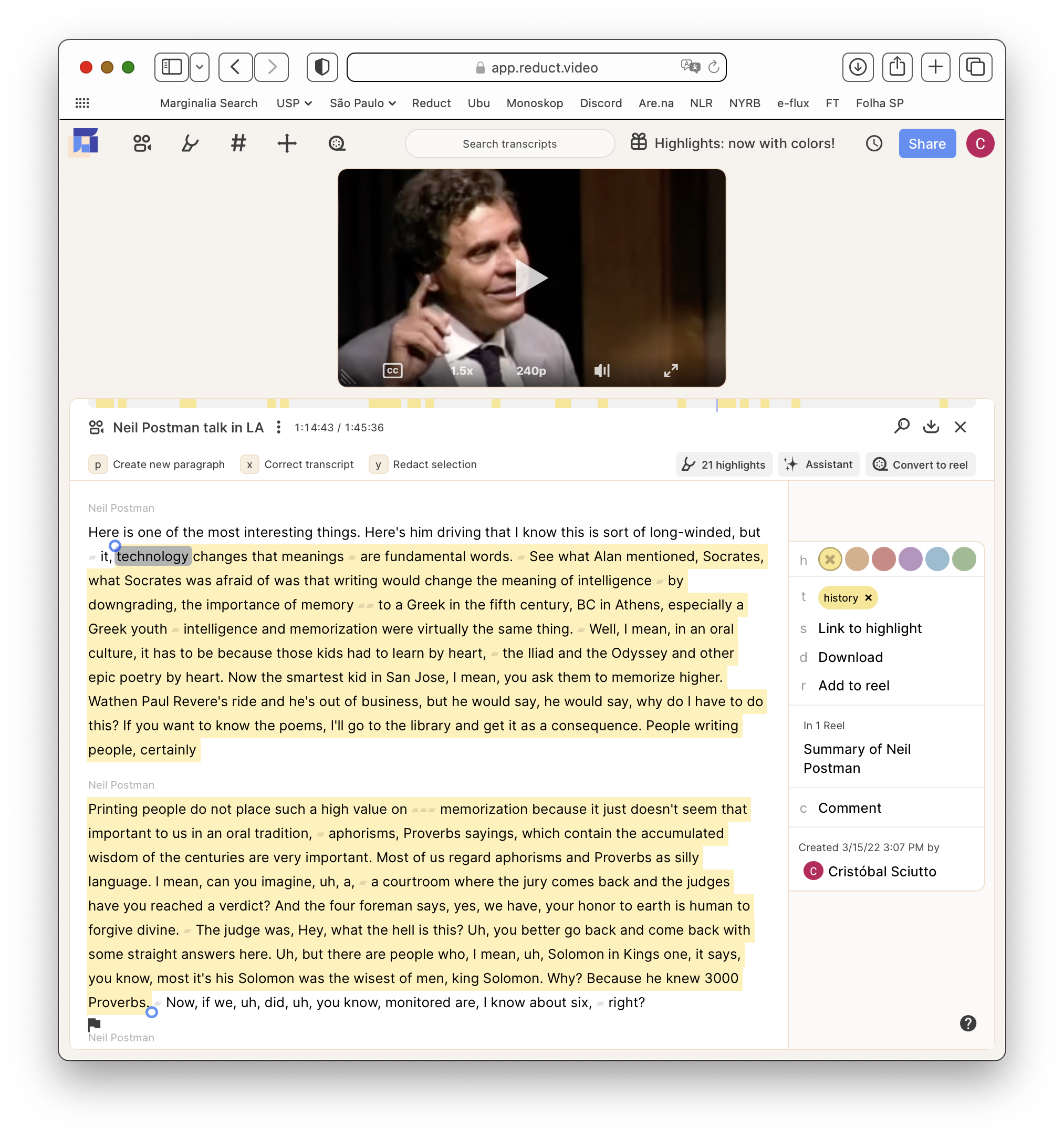
Reduct combines transcription and video playback in a single interface to allow users to easily work with the information inside of videos.
We rely on some principles to develop Reduct that keep the product true to itself, while retaining its variety of uses. Rarely are these made explicit; it's a shared taste the team has developed over years of working together and with different users. One principle we've managed to tease out is a focus on provenance. Everything produced in Reduct links back to its source material.
The product began as just one link: connecting transcripts to the video timeline. With gentle alignment each word is linked to the instant it is uttered and transcripts become a way to navigate video. The source material is the ground truth, and errors in transcription are surfaced by the linking process and during multi-media playback (where text, audio, and video streams intertwine). In our interactive interface, the transcript can be corrected and re-aligned at any moment. More abstractly, derived data such as transcription is presented alongside its referent, grounding it.
Alignment gives some legroom with regard to transcription accuracy. 95%-accurate transcript is good enough to skim and grasp the general thread of a conversation. However, it's not accurate enough to trust as textual evidence in a legal case. With aligned transcripts, this is not a problem: Public defenders transcribe and easily drill down on relevant sections of video evidence (a rapidly growing need since the introduction of body-worn cameras) using our textual interface, without erasing the voices underneath the text. By submitting the linked video, rather than inaccurate and intrinsically ambiguous transcripts, the selection is more readily admitted as legal evidence.
This is worth highlighting: Provenence, linking derived data to its source, allows for data derivation to be both trusted and more experimental.
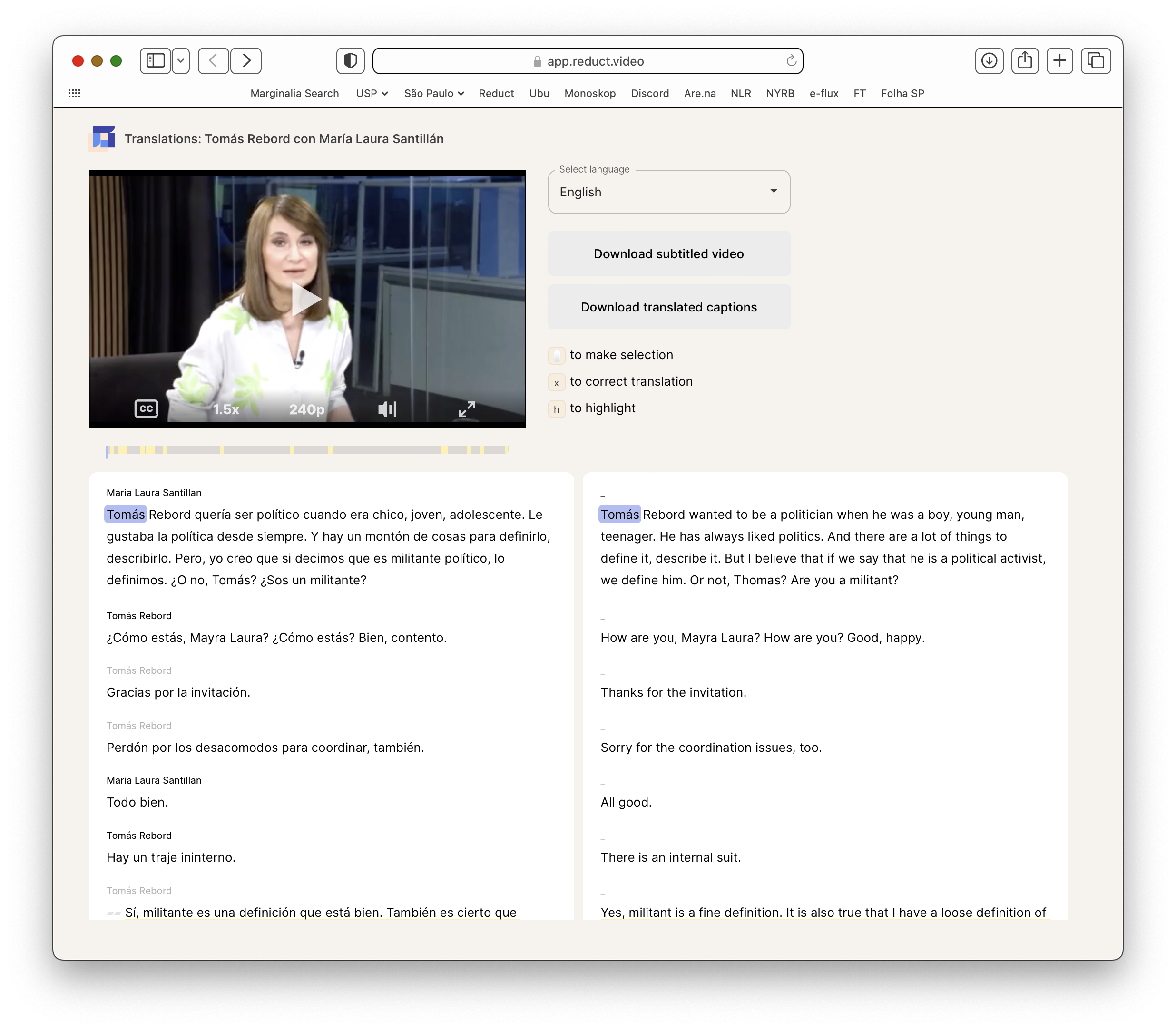
In one of our experimental interfaces, translations are presented side-by-side to the original language. Simulataneous presentation affords verification.
This linked approach informs every part of Reduct. For example, it has allowed us to experiment with transcript translation. Through some clever introspection during transcription, we're able to link translations to the original media. The timestamp when a Spanish newscaster says "el elefante rosado" can be linked to from the translated English-language transcript "the pink elephant." That enables skimming, highlighting, tagging, and even editing video in a language that one is only partially fluent in. And yet, through a translation's imperfections, the underlying words are still heard.
One of our clients, an investigator for a public defense firm with a tight budget, was working on a mitigation video for a client. They had recorded six hours of interviews in Spanish and needed to make an initial edit for the judge. Applying their intermediate Spanish comprehension and our automated translations, they whittled down six hours to a half-hour rough cut. For this they could afford a professional translator to clean up the transcripts and validate that the narrative was faithful to its source material.
So far we've discussed how provenance affords experimentation and trust, guaranteed by simultaneous viewing of the source and the derived data through an interactive interface. A further consequence of provenance is interoperability.
Most of our source material comes in the form of encoded video. Since we require derived data to be linked to its source, all constructed artifacts can be expressed in reference to this standard data format. By tracing back the links, a sequence of clips (an edit) can, for example, be sent off to a professional translator for inspection in the form of a video file. No special interface is needed.
Similarly, an edit in Reduct can be exported to a professional editing tool such as Premiere Pro or Final Cut by constructing XML specifying clips and sources. This enables "proxy workflows" which have been essential to expanding in the professional video market. We’re able to help documentarians with large volumes of material to distill and sequence concise narratives. They can then immediately import the sequence into their professional tool of choice for B-reels, audio mastering, and visual effects. This means that we don't have to build professional editing in house and can focus on our core competencies.
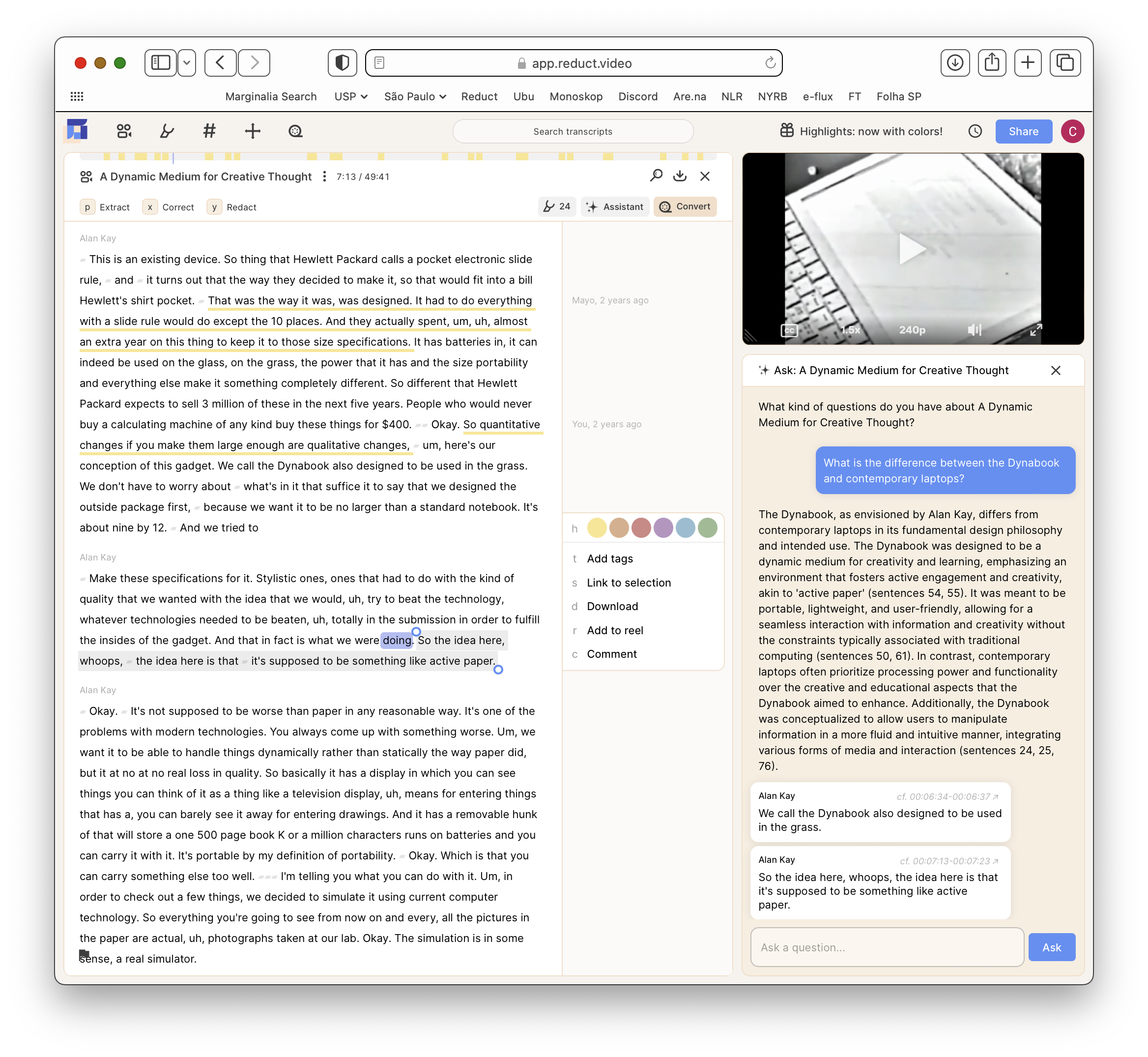
Reduct's "Ask a Recording" panel. We answer user's questions through clips dynamically linked and contextualized within the whole recording.
Our transcription, forced alignment, and translation are all “AI”. Reduct is built on top of the recent statistical revolution in how computational problems are approached. However, our focus on provenance inverts the usual narrative of “magic” which generative AI represents. Instead, it brings the source material to life. This approach to tooling stays with us as we move from supervised ML to the self-supervised approach of LLMs.
Over the past year we've sprinkled in a few LLM-based tools into Reduct. We've introduced summarization of recordings, working hard to link them to the source material. We've also experimented with "topic reels" based on suggested topics extracted from the transcripts. In both cases we make sure that a core Reduct primitive is created by the LLM, which bakes in provenance and allows for the user to validate what is produced. We are now hoping to introduce a chat interface which allows users to "ask a video a question".
Our focus on provenance gives the now very common "chat bot" pattern a unique twist: Rather than centering answers from the LLM, prone to hallucination, we center responses from the speakers in the video itself. Concretely, through structured-output APIs we link relevant clips from the source material to answer the user's questions. Visually, we double-down on the metaphor by foregrounding the speaker's voices over the "magic" personage of the LLM. This is not really groundbreaking, but shows how the principle affects design decisions that have meaningful implications for how a tool is used.
Provenance is the core of Reduct. It grounds derived data in its source material to encourage verification and correction. In doing so it allows experimentation while retaining trust. Further, provenance facilitates interoperability with other platforms. Succintly, we believe that provenance allows for abstraction without indirection. Now, despite all the recent excitement in LLMs, we see no reason to discard this ethos.
Cristóbal Sciutto, August, 2024
Thanks to Chris Beiser, Ned Burnell, and Omar Rizwan for comments and feedback.